固定效应和随机效应的比较研究
引言
固定效应和随机效应是经济学研究中常见的两种模型设定方式。这两种方法都用于处理样本数据中存在的内生性问题,但是它们的设定和适用范围各不相同。本文旨在深入探讨这两种效应方式的应用,为研究者提供更为准确的数据分析和政策解释。
固定效应概述
固定效应模型是一种在面板数据或时间序列数据中处理个体固定效应的方法。它假设每个个体在模型中具有固定的效应,这种效应不受时间或其他解释变量的影响。通过固定效应模型,我们可以控制个体间的差异,从而提高模型的解释力度。
在固定效应模型中,我们通常使用面板数据或时间序列数据,并且每个个体都被视为一个独立的观测单位。在模型估计时,我们通常使用固定效应回归方法,以控制个体间的固定效应。这种方法对于处理异质性个体非常有效,可以更好地捕捉个体间的内生性问题。
随机效应概述
随机效应模型是一种处理面板数据或时间序列数据中存在的内生性问题的方法。它假设每个个体在模型中的效应是随机的,并且受到其他解释变量的影响。通过随机效应模型,我们可以捕捉到个体间的异质性,从而提高模型的解释力度。
在随机效应模型中,我们通常使用面板数据或时间序列数据,并且每个个体都被视为一个观测值集合的一部分。这种方法对于处理高度异质性的个体非常有效,可以更好地捕捉到个体间的内生性问题。随机效应模型的估计结果通常受到混合效应模型的影响,需要谨慎处理。
比较研究
在实际研究中,选择固定效应还是随机效应取决于数据的特性、问题的性质以及研究者的目标。一般来说,如果数据存在明显的个体间异质性或内生性问题,可以考虑使用随机效应模型;如果数据的个体间差异较小,且不需要捕捉这种差异,那么固定效应模型可能更为合适。此外,研究者还可以根据样本大小来选择模型。一般来说,如果样本量较大,可以考虑使用固定效应模型;如果样本量较小,则可以考虑使用随机效应模型。
然而,值得注意的是,尽管随机效应模型在捕捉个体间的异质性方面具有优势,但它可能会忽略个体间的固定效应。因此,在某些情况下,使用固定效应模型可能更为合适。此外,对于一些政策分析问题,固定效应模型可能更为适用,因为它能够更好地捕捉到政策干预的时间趋势和稳定性。此外,考虑到公共政策的制定和实施通常是一个长期的过程,考虑个体间的长期影响和稳定性也非常重要。因此,对于公共政策问题,研究者应综合考虑样本大小、数据的特性以及政策目标等多方面因素,以选择合适的模型进行实证分析。
结论
总之,固定效应和随机效应是经济学研究中常见的两种方法,适用于不同的情况。在选择这两种方法时,需要综合考虑样本大小、数据的特性以及问题的性质。无论使用哪种方法,都应该采用严谨的数据分析方法进行实证研究,以避免误导公共政策制定者的决策和读者对模型的误解。在未来的研究中,我们需要进一步探索如何更有效地使用这两种方法来解决内生性问题,以提高研究的准确性和可信度。






















 查看未读消息
查看未读消息 查看最新消息
查看最新消息










 分享
分享
 复制
复制 全选
全选 总结
总结 解释一下
解释一下 延展问题
延展问题 自由提问
自由提问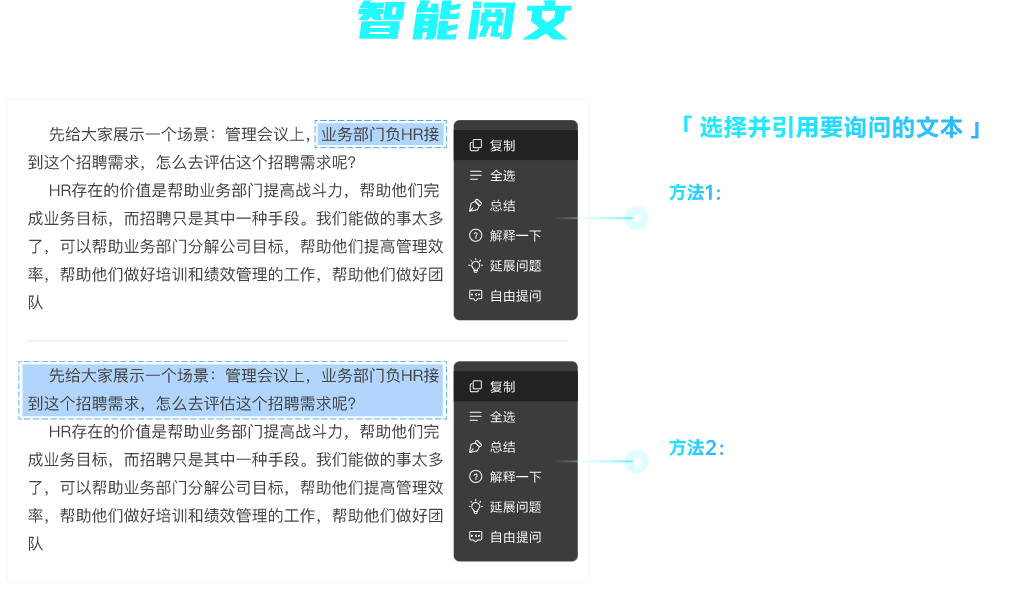












 复制
复制 分享
分享