刘润:我对OpenAI,知之甚少
编辑:言值哥哥
2024-09-06 13:54
276 阅读

今天终于如常所愿。

 AI,是不是过热了?
AI,是不是过热了?
 这一切,都从2012年开始
这一切,都从2012年开始
 AI学习数据的知识产权,到底属于谁?
AI学习数据的知识产权,到底属于谁?
 流量生成器
流量生成器
 美国的AI,会一直领先于中国吗?
美国的AI,会一直领先于中国吗?
 OpenAI,正在憋大招吗?
OpenAI,正在憋大招吗?
 算法:Transformer,一定是最好的架构吗
算法:Transformer,一定是最好的架构吗
 算力:AI能耗,是人类的上万倍
算力:AI能耗,是人类的上万倍
 数据:只有思考结果,没有思考过程
数据:只有思考结果,没有思考过程
 打开思维的疆界
打开思维的疆界(本文来源刘润,如有侵权请联系删除)
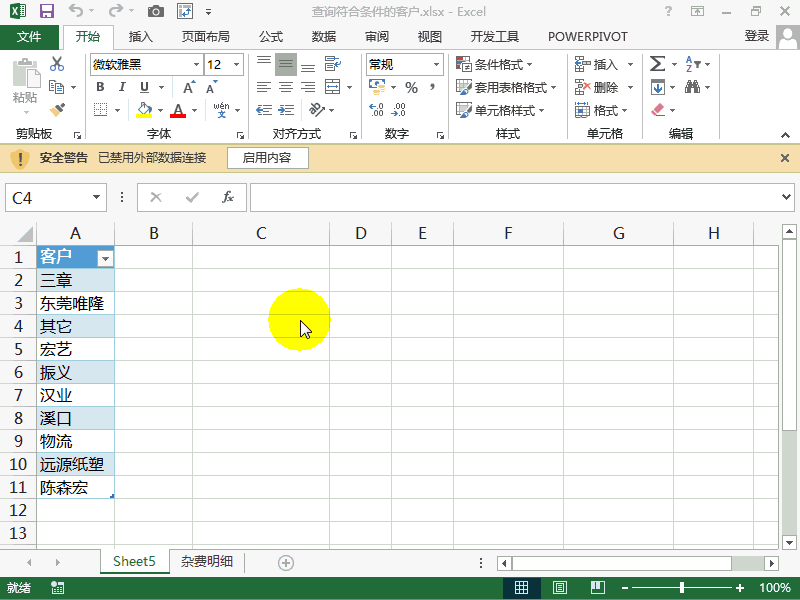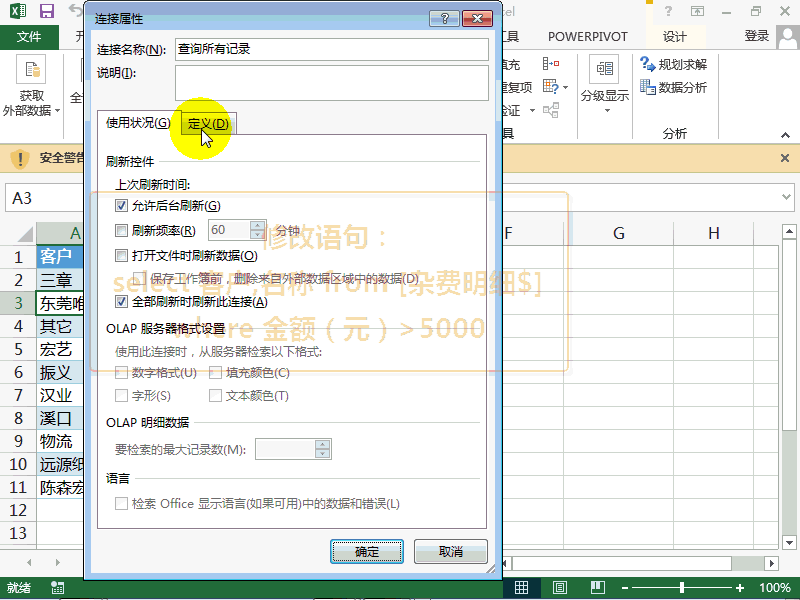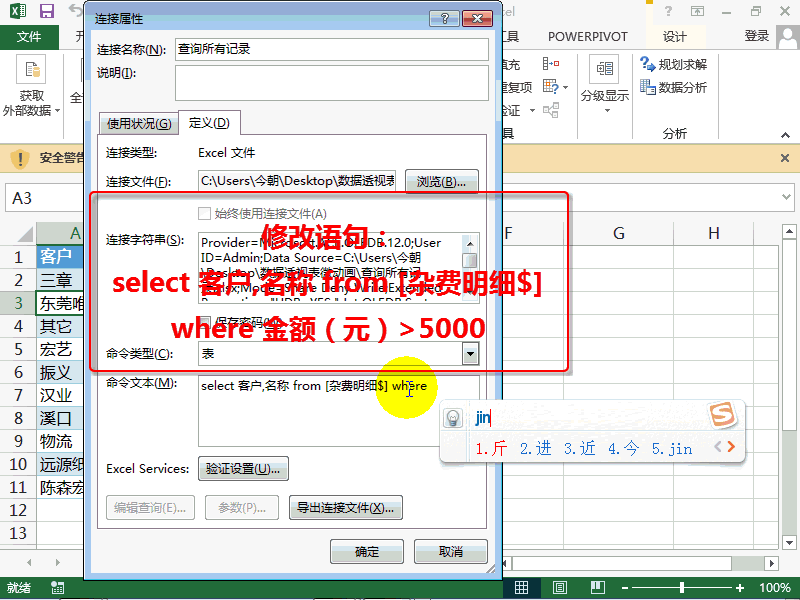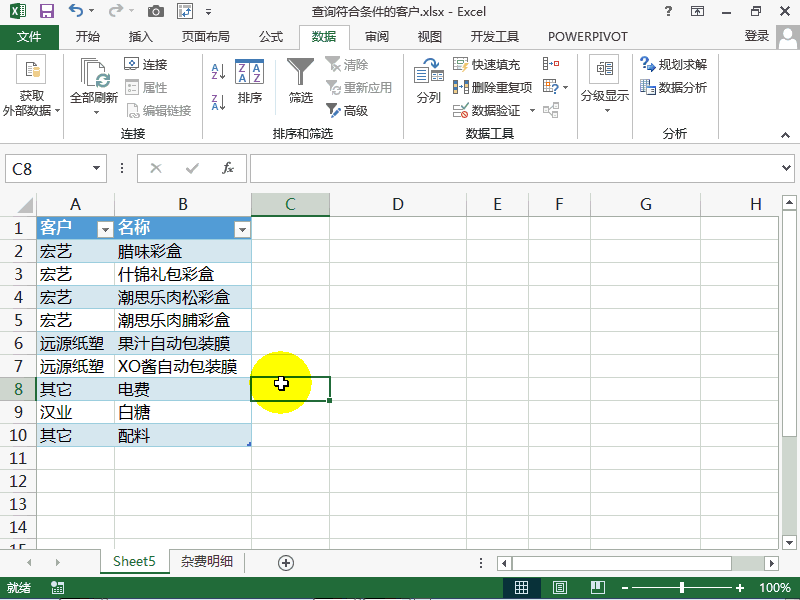
考勤/绩效/工资/社保(680个带公式的Excel模板),一次性拿走 π
讲真,很多职场人用了那么多年的Excel,依然停留在简单的表格绘制和公式运用上。可能有小伙伴会说,“Excel很简单啊,不就是输入数字,然后加减乘除嘛,这是计算器都能完成的工作啊。”这么想就错了!Excel里真正...
2024-08-22 14:30
权威解答!弹性提前、弹性延迟影响养老金吗?
三茅日报丨人力资源相关最新简讯(2024年9月14日)
国产芯片巨头华夏芯轰然倒下,域名资产遭拍卖,行业震动不已
员工拒为部门领导买早餐被辞退?涉事公司回应
跨境电商平台爆雷!欠债大裁员涉全球三地,刚收购Wish
波音公司3.3万员工罢工,美媒:将导致西雅图地区生产停顿
中国华能2025校园招聘全面启动
最新!最高法关于工伤疑难问题的权威答复(2024.09)
【人社日课】员工提出离职,需赔偿公司违约金吗?
张丽俊丨领导最喜欢的,从来不是能力强的员工
张丽俊丨工作能力强的人,凡事都有方法论
在职员工设立同业公司,用人单位能主张赔偿吗?




扫码下载APP

扫码添加公众号

扫码在线咨询















 查看未读消息
查看未读消息 查看最新消息
查看最新消息
更多
消息免打扰
拉黑
不再接受Ta的消息
举报



返回消息中心
群发消息本周还可群发 次
文字消息
图片消息
群发须知:
(1) 一周内可向关注您的人群发2次消息;
(2) 创建群发后,工作人员审核通过后的72小时内,您的粉丝若有登录三茅网页或APP,即可接收消息;
(3) 审核过程将冻结1条群发数,通过后正式消耗,未通过审核会自动退回;
(4) 为维护绿色、健康的网络环境,请勿发送骚扰、广告等不良信息,创建申请即代表您同意《发布协议》
本周群发次数不足~
群发记录
暂无记录
多多分享,帮助他人成长,提高自身价值
群发记录
群发文字消息
0/300
群发
取消

提交成功,消息将在审核通过后发送
我知道了






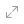
 分享
分享
 复制
复制 全选
全选 总结
总结 解释一下
解释一下 延展问题
延展问题 自由提问
自由提问












 复制
复制 分享
分享