数据加权是什么意思
在数据分析和统计中,数据加权(Data Weighting)是一种重要的技术手段,其基本思想是根据不同数据点的重要性或可信度赋予不同的权重值。这样可以在数据分析时更准确地反映实际情况,避免因为某些数据点的极端值或特殊情况对整体分析结果造成的影响。下面将详细介绍数据加权的概念、应用场景及具体操作方法。
一、数据加权的概念
数据加权是一种对数据进行处理的方法,它通过给每个数据点分配一个权重值来调整其在整体分析中的影响力。权重值通常是一个介于0和1之间的数值,其中1表示该数据点在分析中具有最大的影响力,而0则表示该数据点在分析中不具有任何影响力。
二、数据加权的应用场景
1. 样本调查:在样本调查中,由于不同样本的抽样方法和可信度可能存在差异,因此可以通过加权来调整不同样本在总体分析中的重要性。例如,在民意调查中,不同年龄、性别、地域等人群的样本应赋予不同的权重,以反映其在实际人口中的比例。
2. 多元回归分析:在多元回归分析中,由于各因素对目标变量的影响程度可能存在差异,因此可以利用加权方法来反映各因素的相对重要性。
3. 金融领域:在金融领域中,数据加权常用于股票指数计算、风险评估等方面。例如,在计算股票指数时,可以根据不同股票的市值、流通性等因素赋予不同的权重。
三、数据加权的操作方法
1. 确定权重分配原则:根据实际情况和需求,确定各数据点的权重分配原则。例如,在样本调查中,可以根据不同人群在总体人口中的比例来分配权重。
2. 计算权重值:根据确定的权重分配原则,计算每个数据点的权重值。常用的方法包括等权重法、专家打分法、层次分析法等。
3. 加权计算:将每个数据点的值与其对应的权重值相乘,得到加权后的值。然后根据这些加权后的值进行进一步的分析和计算。
四、注意事项
1. 数据准确性:在进行数据加权时,必须确保原始数据的准确性。如果原始数据存在错误或偏差,那么加权后的结果也将不准确。
2. 合理分配权重:在确定权重分配原则时,应充分考虑各因素的实际影响程度和可信度。如果权重分配不合理,可能导致分析结果偏离实际情况。
3. 避免过度依赖:虽然数据加权可以提高分析的准确性,但并不能完全消除误差。因此,在使用加权结果时,应避免过度依赖和误解。
五、总结
总之,数据加权是一种重要的数据处理方法,它可以根据不同数据点的重要性或可信度赋予不同的权重值,从而提高分析的准确性。在实际应用中,我们应根据实际情况和需求确定权重分配原则,并采用合适的加权方法进行计算和分析。






















 查看未读消息
查看未读消息 查看最新消息
查看最新消息










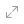
 分享
分享
 复制
复制 全选
全选 总结
总结 解释一下
解释一下 延展问题
延展问题 自由提问
自由提问












 复制
复制 分享
分享